NeRF-MAE: Masked AutoEncoders for Self-Supervised 3D Representation Learning for Neural Radiance Fields
arXiv Paper Code Model Weights Dataset Narrated Video
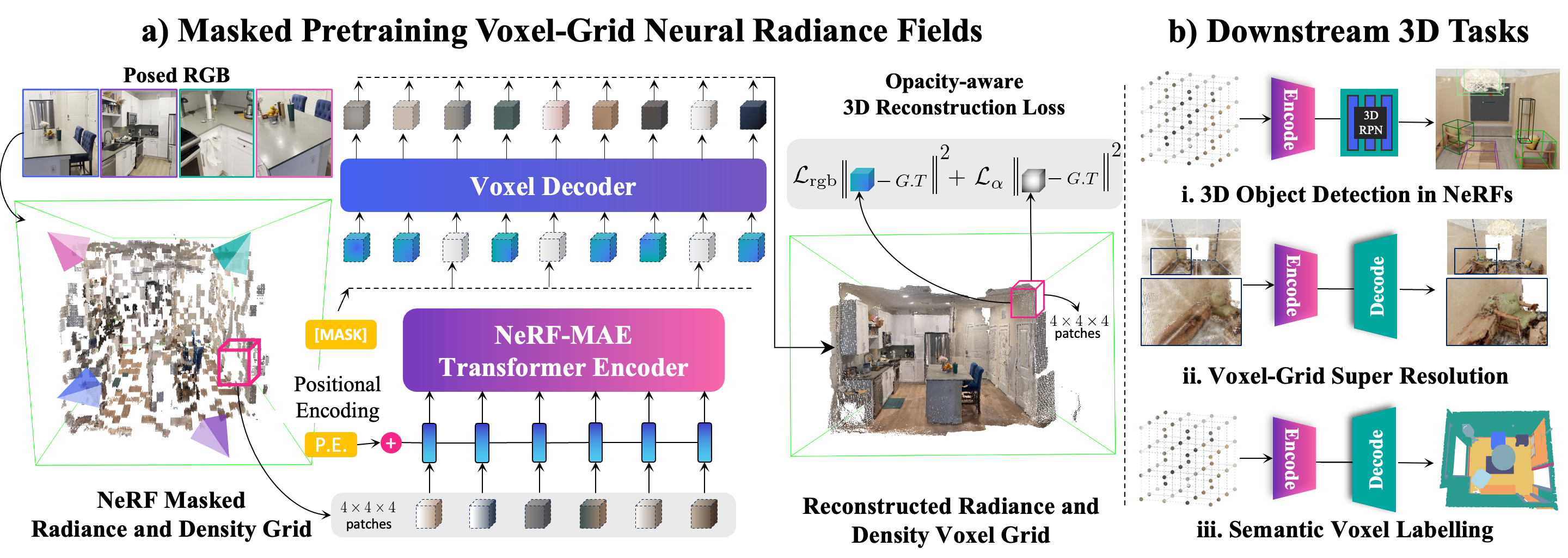
Overview: a) We present NeRF-MAE, the first large-scale self-supervised pretraining utilizing Neural Radiance Field’s (NeRF) radiance and density grid as an input modality. Our approach uses a standard 3D Swin Transformer encoder and a voxel decoder to learn a powerful representation in (a) an opacity-aware dense volumetric masked self-supervised learning objective directly in 3D. (b) Our representation, when fine-tuned on a small subset of data, improves many 3D downstream tasks such as 3D object detection, voxel super-resolution, and voxel-labeling.
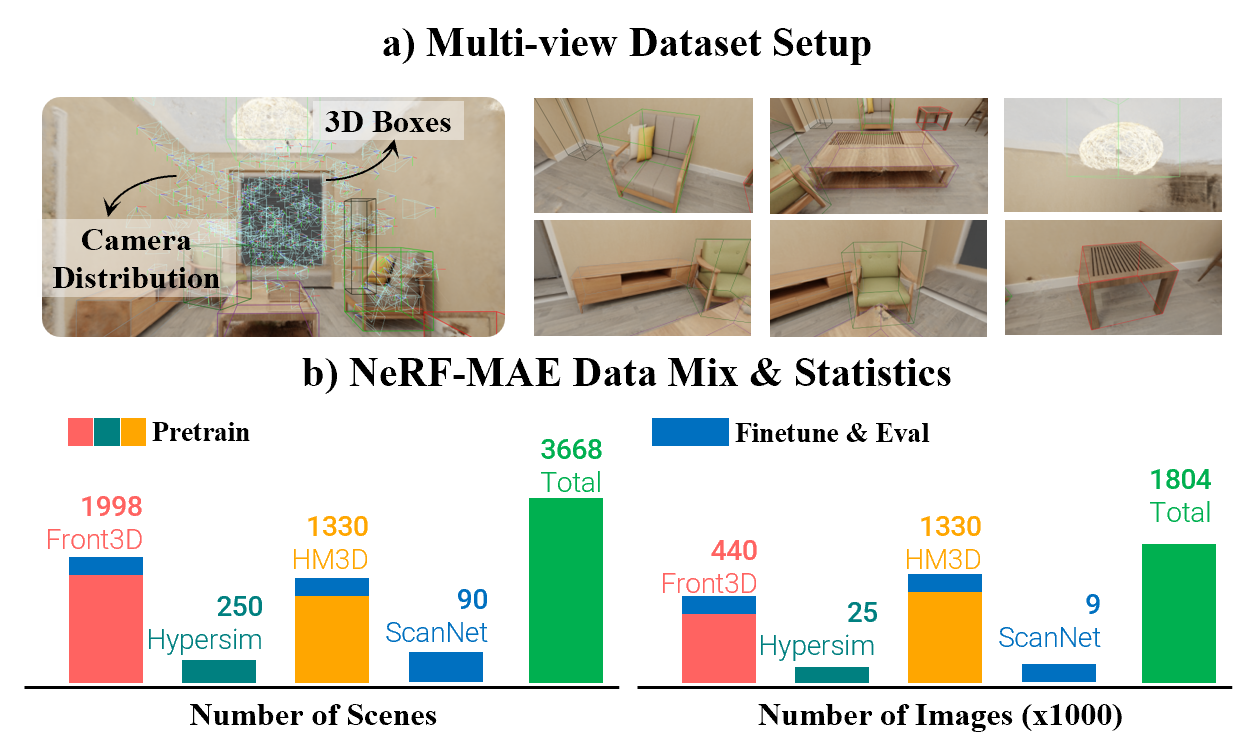
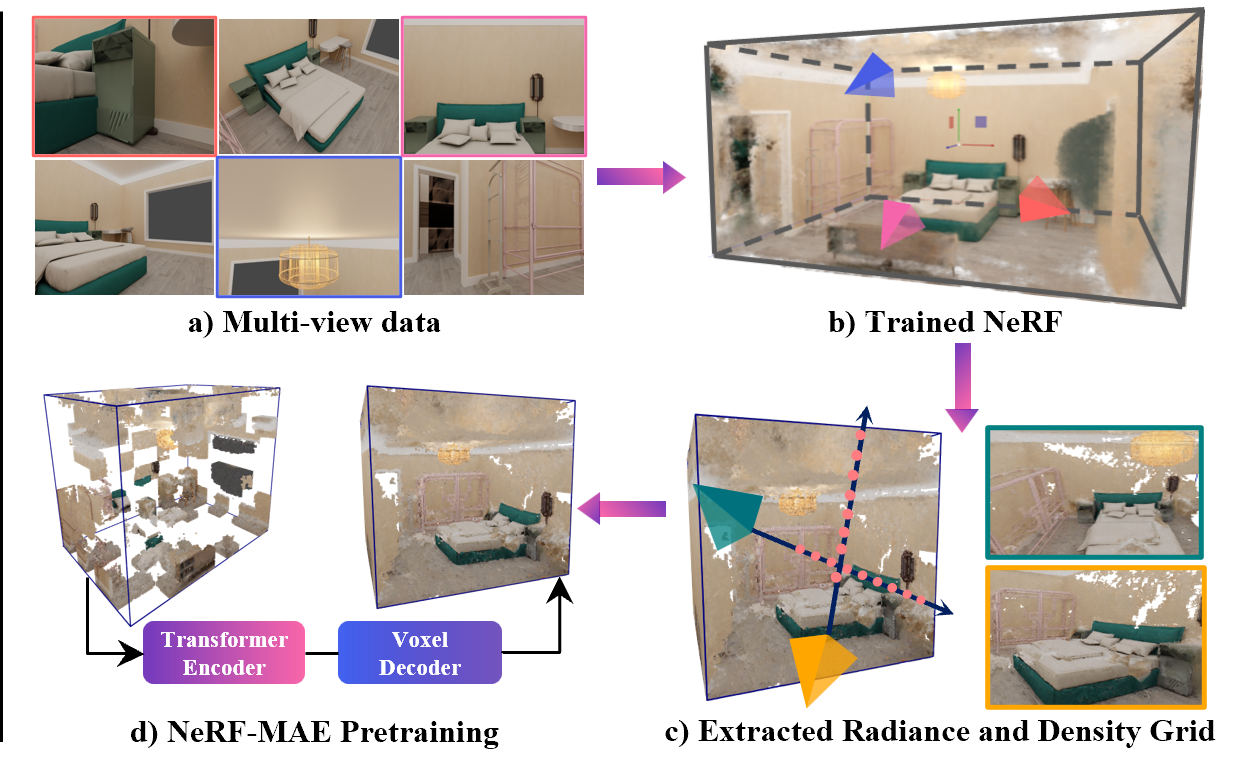
We pretrain a single Transformer model on large-scale diverse scenes from 4 different data sources i.e. Front3D, Hypersim, Habitat-Matterport 3D and test on hold-out ScanNet scenes. Our dataset-mix for pretraining and evaluation totals over 3600 scenes and over 1.8M images used for pertaining neural radiance fields using our single model i.e. NeRF-MAE
Abstract
Neural fields have shown remarkable success in computer vision and robotics due to their ability to understand the 3D visual world such as inferring semantics, geometry, and dynamics. Given the capabilities of neural fields in densely representing a 3D scene from 2D images, we ask the question: Can we scale their self-supervised pretraining, specifically using masked autoencoders, to generate effective 3D representations from posed RGB images. Given the astounding success of extending transformers to novel data modalities, we employ standard 3D Vision Transformers to suit the unique formulation of NeRFs. We leverage NeRF's volumetric grid as a dense input to the transformer, contrasting it with other 3D representations such as pointclouds where the information density can be uneven, and the representation can be irregular. Due to the difficulty of applying masked autoencoders to an implicit representation, such as NeRF, we opt for extracting an explicit representation that canonicalizes scenes across domains by employing the camera trajectory for sampling. Our goal is made possible by first masking random patches from NeRF's radiance and density grid and employing a standard 3D Swin Transformer to reconstruct the masked patches. In doing so, the model can learn the semantic and spatial structure of complete scenes. We are able to pretrain this representation at scale on our proposed carefully curated posed-RGB data, totaling over 1.6 million images. Once pretrained, the encoder backbone is used for effective 3D transfer learning. Our novel self-supervised pretraining approach for NeRFs, NeRF-MAE, scales remarkably well and improves performance on various challenging 3D tasks including 3D object detection, voxel super-resolution, and semantic labeling. Utilizing unlabeled posed 2D data for pretraining, NeRF-MAE significantly outperforms self-supervised 3D pretraining and NeRF scene understanding baselines on Front3D and ScanNet datasets with an absolute performance improvement of over 20% AP50 and 8% AP25 for 3D object detection.
NeRF-MAE Comparison
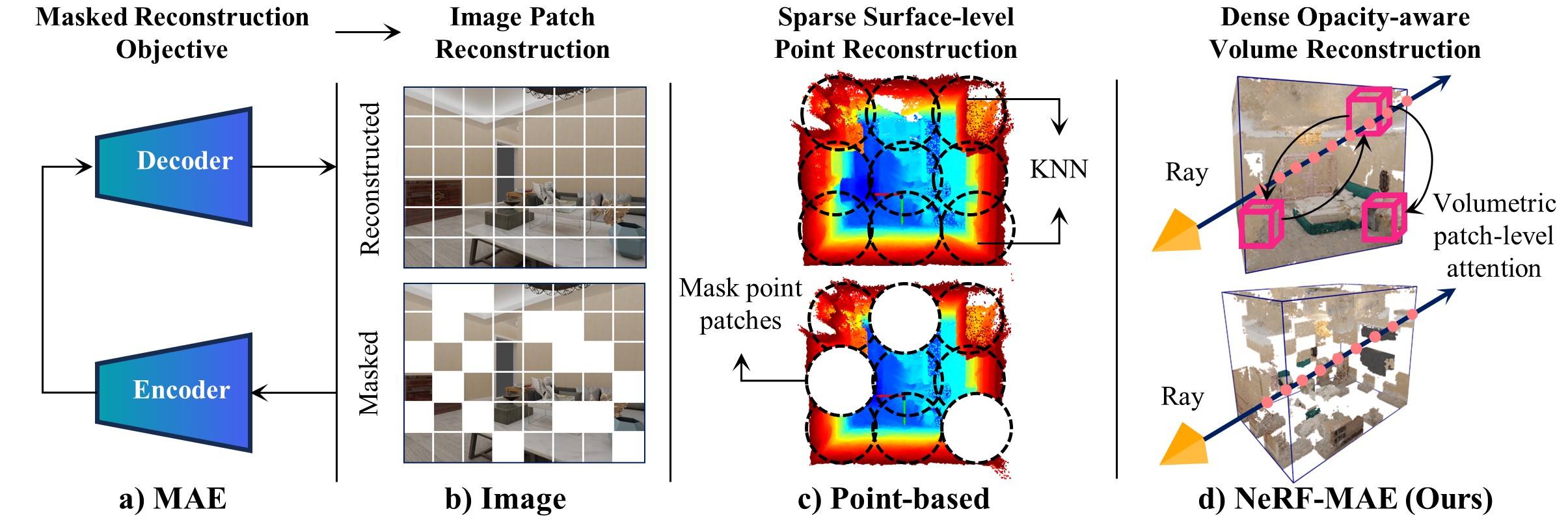
We show detailed comparison to point-based pretraining approaches in our paper. We note their limitation as they model surface-level sparse points, where our approach is similar to images in terms of high-information density and regularity of structure; hence making NeRF-MAE a direct extension of image MAE to 3D. We leverage NeRF’s dense volumetric information along rays and introduce an opacity-aware reconstruction loss, enabling us to achieve superior representation learning. For detailed results, please refer to our paper's experimental section.
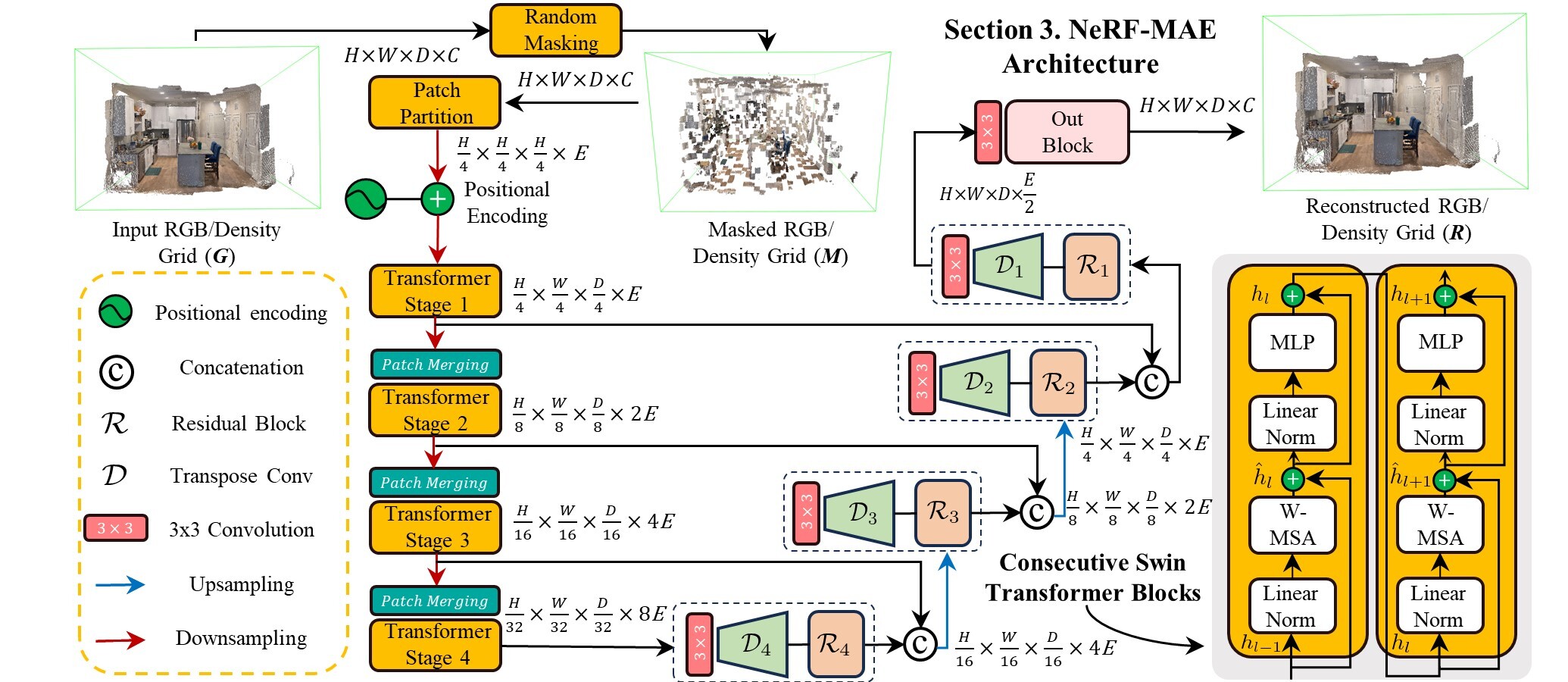
Method
Our method utilizes a U-Net style architecture employing Swin Transformer as the encoder to encode the RGB/density grid into meaningful multi-resolution low-level features, and transposed convolution layers at each stage with skip connections using residual blocks from the features of the encoder. We use mask volume region reconstruction, and enforce a faithful and accurate reconstruction of masked patches with a custom opacity and radiance-aware loss function suited to the unique formulation of NeRFs.
Narrated Video
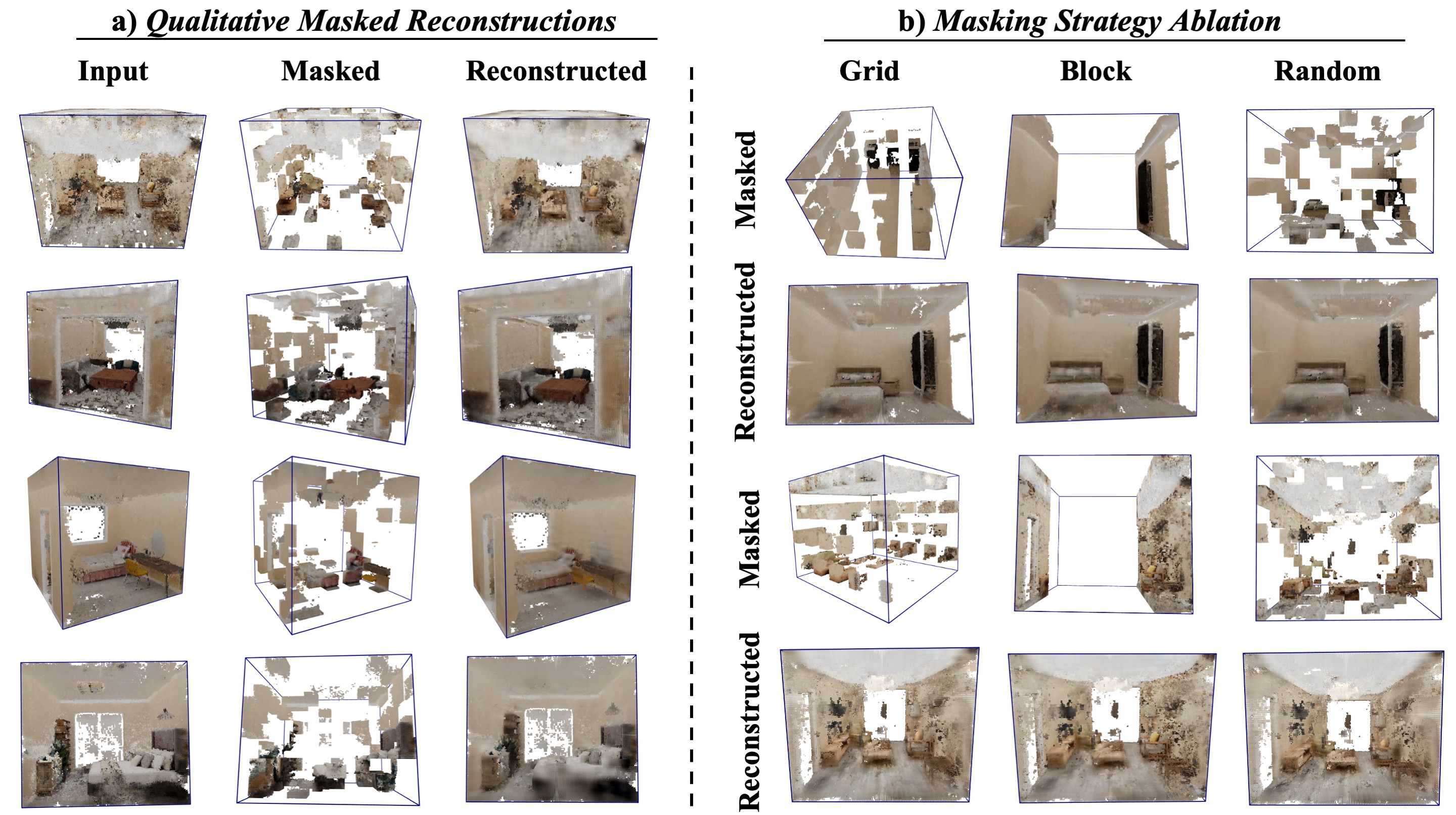
Qualitative NeRF-MAE Reconstructions
Left: For each triplet, we show ground truth (left), masked radiance and density grid (middle) and our NeRF-MAE reconstruction overlayed with unmasked GT grid (right). The masking ratio is 75%, leaving only 250 patches out of 1000 patches. Right: shows different masking strategies along with the reconstructed output
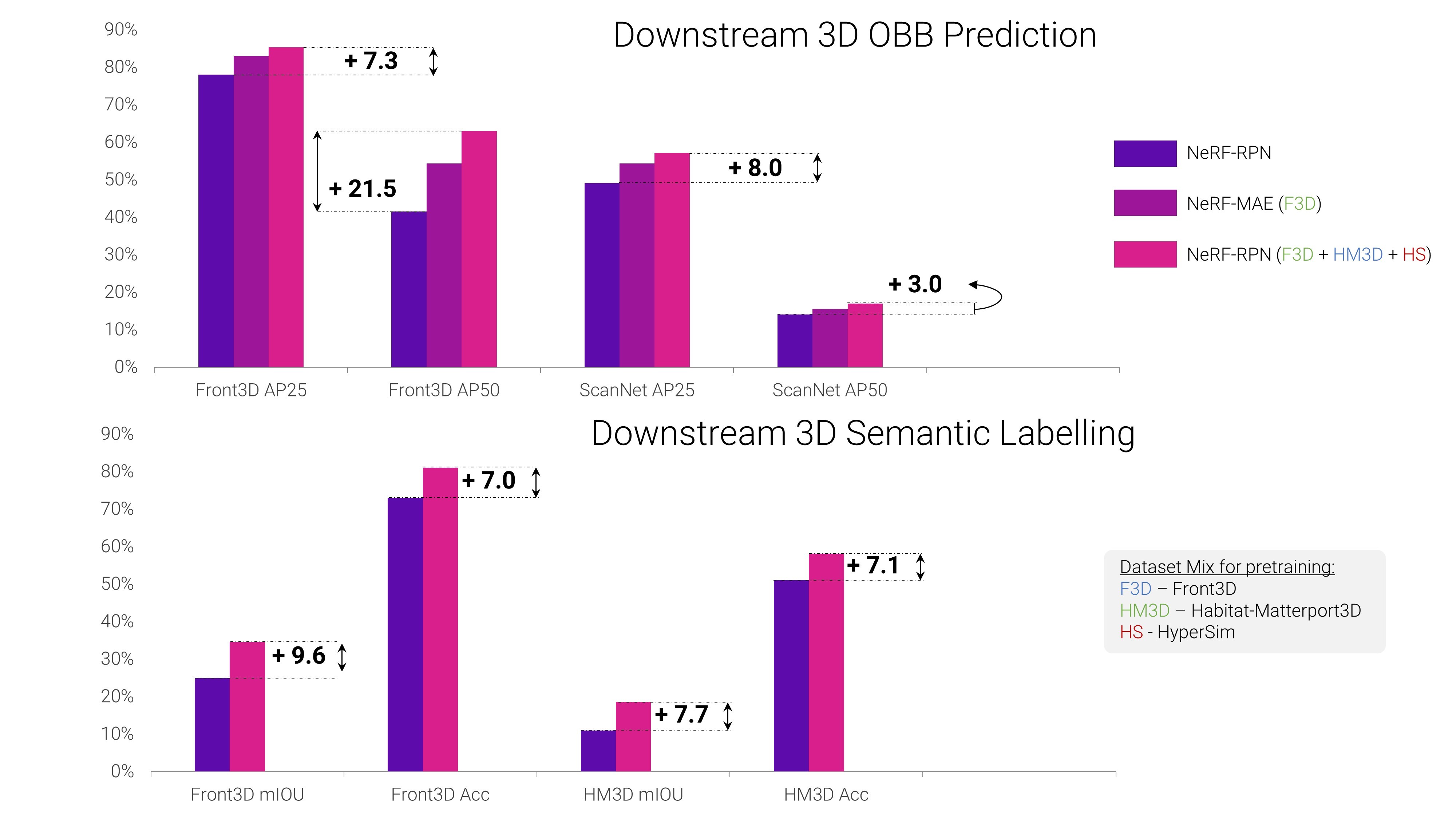
Quantitative Comparisons
Quantitative evaluation results shows our pretraining improves a variety of downstream 3D tasks on both unseen in-domain data (Front3D) and out-of-domain data (ScanNet). We also show that adding unlabelled posed 2D data from different sources improves performance on 3D OBB prediction downstream task. For detailed analysis, please refer to our paper's experimental section.
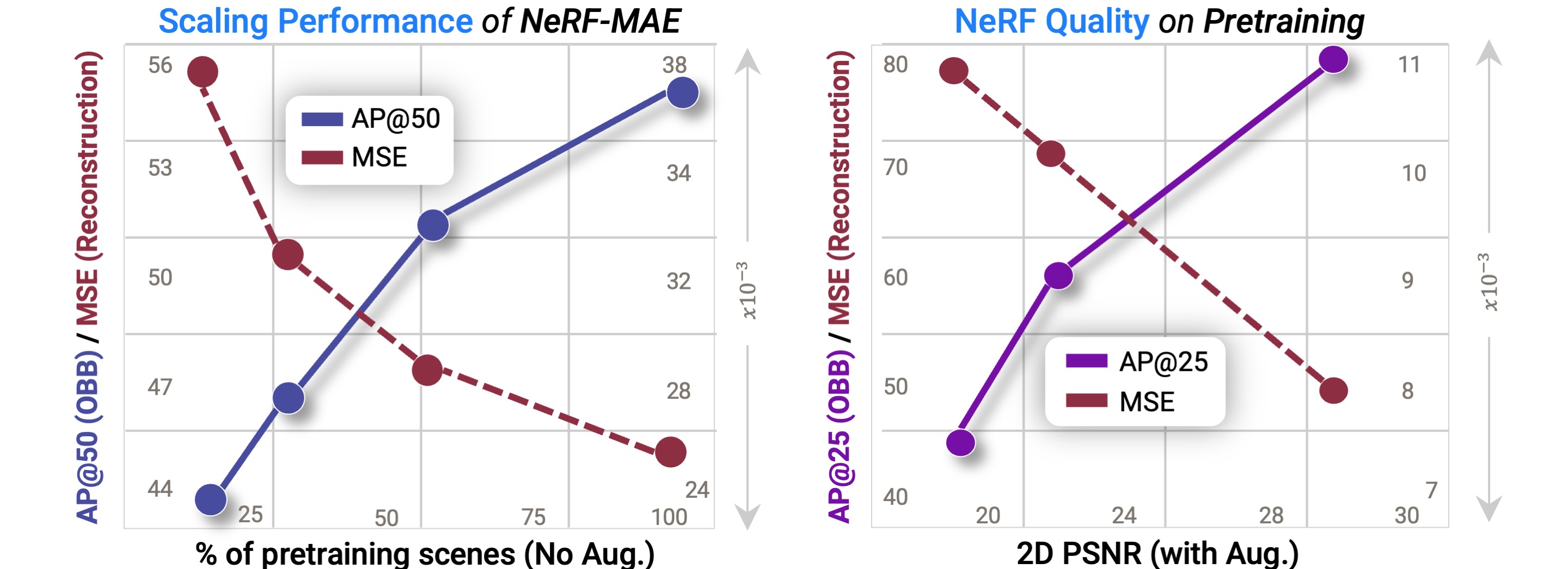
Scaling Performance and Ablation Analysis
Quantitative results showing our representation improves with more unsupervised data and as well as better reconstruction quality of input NeRF.
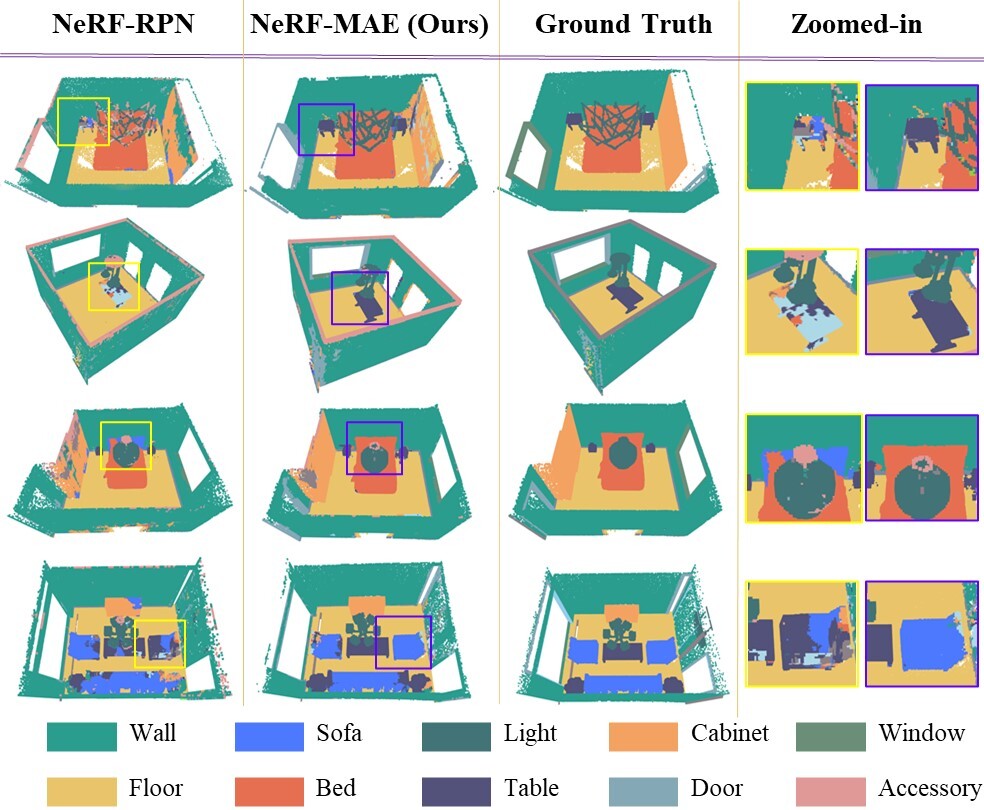
Downstream 3D Tasks Results
Left: Qualitative 3D OBB prediction: showing our approach’s superior results compared with NeRF-RPN Right: Qualitative voxel-labelling downstream task gneralization comparison: showing our approach’s superior results compared with NeRF-RPN.

Citation
@inproceedings{irshad2024nerfmae,
title={NeRF-MAE: Masked AutoEncoders for Self-Supervised 3D Representation Learning for Neural Radiance Fields},
author={Muhammad Zubair Irshad and Sergey Zakharov and Vitor Guizilini and Adrien Gaidon and Zsolt Kira and Rares Ambrus},
booktitle={European Conference on Computer Vision (ECCV)},
year={2024}
}